The Unicode Standard provides a consistent way to digitally represent the characters used in the written languages of the world. As an accepted universal standard in the computer industry, the Unicode Standard assigns each character a unique numeric value and name. This encoding standard provides a uniform basis for processing, storing, searching, and exchanging text data in any language.
In Concordance Desktop, the Unicode Standard is supported in Arabic, Chinese, English, Hebrew, Japanese, Korean, Russian, and other languages.
|
Some Adobe PDF files with Arabic text do not display the Arabic text in the proper right-to-left order in Concordance Desktop. These PDF files display the text in reverse order (left-to-right) because the files report the language incorrectly or are not in the standard format. |
Installation and Database Compatibility
Supporting the Unicode Standard requires the following installation and database changes:
Installing Language Packs
To display characters in Unicode within Concordance Desktop, the appropriate language packs need to be installed on the computer.
For more information, see Installing language packs.
Concordance Installation Changes
Concordance Desktop installs to a new default folder, …\CloudNine\Concordance Desktop, and includes a new Add or Remove Programs dialog box entry and a new registry key. This allows Concordance Desktop and prior versions of Concordance to exist on the same computer.
Database Compatibility
Due to the major database structure changes required by the Unicode Standard, all databases need to be converted to Concordance version 10.x and then to Concordance Desktop. Earlier database versions cannot be opened in Concordance version 10.x or Concordance Desktop. Only Concordance database versions 7, 8, or 9 can be converted to Concordance version 10.x, and only Concordance 10.x databases can be migrated to Concordance Desktop.
Since there is no backwards compatibility to older database versions in Concordance Desktop or Concordance version 10.x, opening a database version 7, 8, or 9 in Concordance 10.x prompts the user to convert the database to version 10. When opening a Concordance version 10.x database in Concordance Desktop, the database is automatically migrated to Concordance Desktop database format.
All Concordance version 10.x databases in a selected folder and subfolders can be converted to Concordance Desktop. For more information, see Migrating databases.
Import Issues and Tips
Currently, the Unicode Standard is supported when importing, searching, printing, and exporting documents in the languages listed above. However, certain issues and tips are important to know when using these features with a non-English document.
The following issues and tips are important to know when importing non-English documents:
Right-To-Left Documents
When importing documents with Right-To-Left (RTL) languages, such as Arabic, the imported text may be incorrectly justified to the left side. To correct this and change the justification to the right side, select the text and press the right [Ctrl] +right [Shift] keys.
Microsoft Excel Files
When importing Microsoft Excel files in Right-To-Left (RTL) languages, the spreadsheet cells may be displayed Left-To Right instead of Right-To-Left.
File Names
Native and/or text file names containing Unicode characters are supported in Concordance Desktop. However, Unicode characters are not supported for use in user IDs, user groups, matters, clients, or database file names.
Delimiters
The delimiters available from the drop-down lists in the Import Wizard, Import Delimited Text dialog box, and the Overlay Database dialog box may appear as square symbols or may not be displayed. How the lists are displayed depends on the computer's language environment.
The delimiters listed below use the Tahoma font, which displays the characters regardless of the language environment. All of the characters listed below can be selected as a delimiter, even if the symbols they represent do not appear in the drop-down lists.
To see the list of available delimiter characters, see About delimiter characters.
Search Issues and Tips
The Unicode Standard is supported when searching documents in Concordance Desktop. For more information about searching, see Available search tools.
The following issues and tips are important to know when searching non-English documents:
Removing Kashida Characters
Kashida characters are used in Arabic text to lengthen a word by elongating characters at certain points. The added Kashida characters change the word.
For example, the word for Term in Arabic is ![]() . When Kashida characters are added, the word changes to
. When Kashida characters are added, the word changes to ![]() .
.
Searching for the word Term with Kashida characters results in inaccurate search results since it will not include the word Term without Kashida characters.
To prevent inaccurate searches, the Concordance Desktop administrator can remove the Kashida characters from the searchable text in the current database.
To Remove Kashida Characters
1.On the File menu, point to Administration, and then click Remove Kashida characters.
2.Enter the administrator user name and password.
3.Click Yes to confirm.
|
The Kashida character removal is permanent and there is no process to convert back to the earlier version. We recommend you make a backup copy of the databases before performing this action. |
i.Kashida characters are automatically removed from the current database. The status is displayed in the Global Replace dialog box. When finished, the dialog box closes.
4.Reindex the database after the Kashida characters have been removed to update the database with these changes.
i.For more information about reindexing, see Indexing and reindexing updates.
Words that Sound Like the Selected Word
When doing an Advanced Search from the Search task pane, selecting Display a list of words that sound like the selected word (also known as Fuzzy Search) only works with English language words. Using this option with words in other languages will display a list of words that do not sound like the selected word.
For more information about Fuzzy Search, see Using the Advanced Search panel.
Navigating Search Results for Ideographic Languages
A character in an ideographic language, like Chinese, can represent a word. When navigating search results, each character is considered a separate hit. Clicking the Next hit and Previous hit buttons jumps to the next character in the search results.
For example, if your search term is the Chinese word for Mandarin Language School (国語学院) you will need to click Next hit four times for each word.
Search Examples
Here are examples of searching Arabic and Japanese documents in Concordance Desktop.
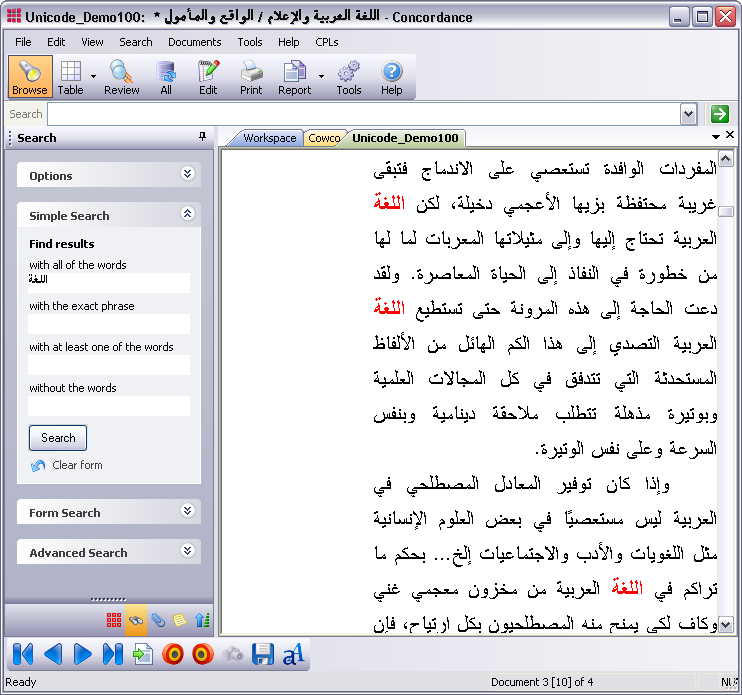
Simple Search in Arabic
You can use Simple Search to find non-English words in your documents. The example below shows how Simple Search is used to find the word ![]() , which means language in Arabic.
, which means language in Arabic.
|
Some Adobe PDF files with Arabic text do not display the Arabic text in the proper right-to-left order in Concordance Desktop. These PDF files display the text in reverse order (left-to-right) because the files report the language incorrectly or are not in the standard format. |
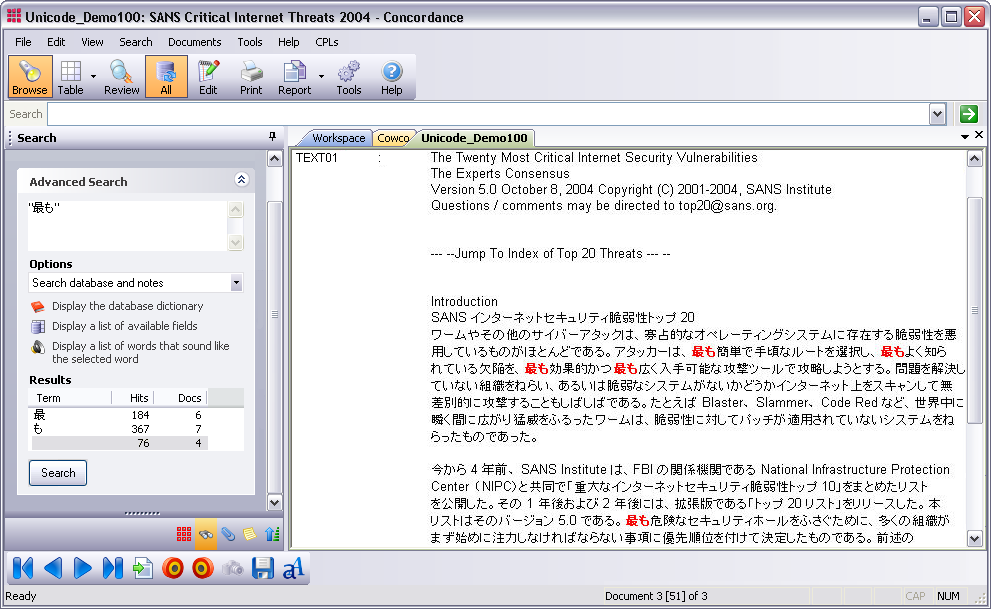
Advanced Search in Japanese
Advanced Search can also be used to find non-English words in your documents. The example below shows an Advance Search for the word "最も", which means most importantly in Japanese.
Edit Issues and Tips
The Unicode Standard is supported when using the Edit features in Concordance Desktop. For more information editing in Concordance Desktop, see About editing records.
The following issues and tips are important to know when using the Edit features with non-English documents:
Data Validation Options
Database fields can be assigned data validation options from the Data Entry Attributes dialog box. However, certain validation options are only supported with English text. These include:
•Upper case
•Lower case
•Alphabetic only
•Numeric only
For more information about data validation, see Creating databases.
Match Whole Word Only
When searching for text using the Find or Replace commands, the Match whole word only check box does not work with ideographic languages such as Chinese. Clear the Match whole word only check box before searching for text in these languages.
Print Issues and Tips
The Unicode Standard is supported when printing documents in Concordance Desktop.
The following issues and tips are important to know when printing non-English documents:
Additional Options for Hit Highlighting
When printing documents with ideographic text, like Chinese, a character underlined for hit highlighting can easily be confused with other characters.
To allow hit highlighting in these languages, additional options have been added to the Formatting tab in the Print documents dialog box. Now you can use underline, bold, italics, color formatting or a combination of these options to highlight the search hits in your reports.
For more information about using the Formatting tab, see Printing standard reports.
Export Issues and Tips
The Unicode Standard is supported when exporting documents from Concordance Desktop. For more information about exporting documents, see About exporting data.
The following issues and tips are important to know when exporting non-English documents:
Exporting to ANSI or ASCII Format
You can export data from Concordance Desktop to ANSI or ASCII format. The file can then be imported into an application that does not support the Unicode Standard; for example, into Concordance 2007 or earlier versions.
This option is available for delimited text files in the Export Wizard dialog box and the Export Delimited ASCII dialog box. It is also available when exporting database transcripts.
|
When exporting to ANSI or ASCII format, characters that cannot be represented as a single-byte character will be lost in the export. So exporting documents with double-byte characters, such as Chinese, to ANSI or ASCII format will result in data loss. See the example below. |
Example of exporting a document with Chinese characters to ANSI
Here is a document with Chinese characters in Concordance Desktop.
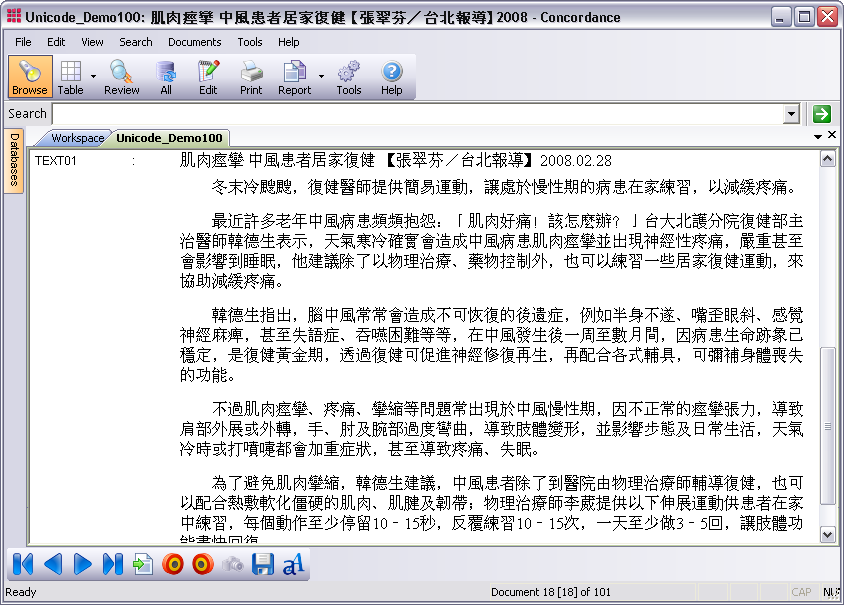
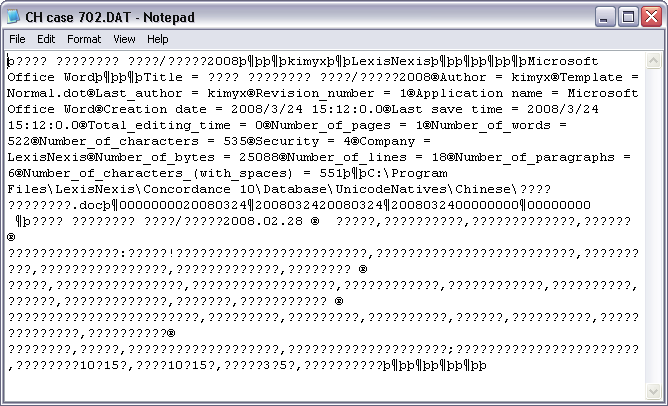
If you export this document to a delimited text file and select the Export ANSI (Export Delimited ASCII dialog box) or Export in ANSI format (Export Wizard - Save dialog box) check box, the Chinese characters will be lost. For example, when you open the exported document in WordPad, the Chinese characters are displayed as question marks (?).
Delimiters
The delimiters available from the drop-down lists in the Export Wizard and the Export Delimited ASCII dialog box may appear as square symbols or may not be displayed. How the lists are displayed depends on the computer's language environment.
The delimiters listed below use the Tahoma font, which displays the characters regardless of the language environment. All of the characters listed below can be selected as a delimiter, even if the symbols they represent do not appear in the drop-down lists.
To see the list of available delimiter characters, see About delimiter characters.
|
When sending data to a 3rd party software program using the Send To command, only ANSI text is sent.. |
|
The Concordance Desktop server does not support user names, passwords, or database names containing characters in Unicode, such as Chinese or Japanese characters. Currently, the server only support user names, passwords, or database names containing single-byte characters, such as English characters. Ensure that you only use single-byte characters when creating user names, passwords, and database names in Concordance Desktop. |