Return to Section Header
You can split a document into multiple documents. Splitting may be configured to split every page of a document into its own document. Splitting may also be based on page selection, barcode pages, or by the presence of blank pages.
|
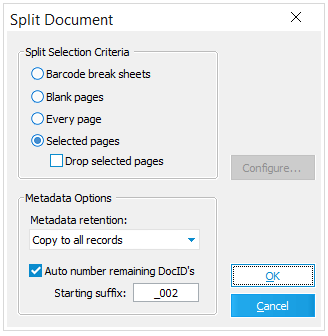 Select a document.
Select a document.Option |
Description |
||
|---|---|---|---|
Barcode Break Sheets |
Processes documents in compliance with any barcode break sheets that are detected, and then removes the barcode break sheets from the page output. •Splits the document if a document break is detected. •Creates a new folder if a folder break is detected. •Separates attachments if attachment sheets are detected. Deletes from the image after being processed. •Click the Configure button for more supported barcode settings and types. You can specify break sheet settings from the Imaging tab of the Options form. If no pages with barcode breaks are found, the operation will be canceled. This setting may be useful if the Detect Barcode Breaks scan option was disabled while scanning. See the Using Barcodes topic for additional barcode information.
|
||
Blank Pages |
Removes blank pages from the document. Detection of blank pages may be configured as follows: •Click the Configure button for blank page filter options. These options are listed as follows: Pristine White. Removes pages only if they completely blank and contain no discernable visual noise. This option is best used for electronic documents that were converted directly to TIFF or PDF. Scanned images may require a slightly less sensitive filter. Dirty White. Removes pages that are blank even if a small amount of visual noise is detected. Visual noise includes such things as speckles, creases, and folds. This setting is recommended for scans of good or excellent quality scanned documents. Very Dirty White. Removes pages that are blank even if a large amount of visual noise is detected. This setting is recommended for scans of poor quality documents. One Line Acceptable. Removes pages that contain a single line of text, for example, "This page intentionally left blank".
|
||
Every Page |
Splits every page of the document into its own single-page document.
|
||
Selected Pages |
Designates the currently selected pages as the starting page of new documents. This setting is only available if one or more pages are selected. Because the first page (of the current document, prior to splitting) is automatically included as the start of the first sub-document, selection of this page is not necessary.
|
||
Drop Selected Pages |
Drops all selected pages. This will also be the case if barcode break sheets or blank pages as the separator pages are manually selected. |
||
Metadata Options (for ED Records) |
Use these options for records imported with ED Loader and then converted to TIFF using CloudNine™ LAW. Discard all metadata. Removes all ED import metadata associated with the original record, with the exception of the DocID field. This includes important values used to indicate duplicate record status, metadata pulled from the native file, and ED Loader session information.
Copy to all records. Records created by the split inherit the metadata of the original record. The original native file will be associated with all new records. The native file is not copied; all new records will point to the same file. For new records beyond the first record, this native file link is created by placing the path to the native file into the "NativeFile" field in the LAW case. Because of this behavior, if the newly split records are included in a TIFF conversion process, the same native file will be converted for each of the records involved in the split. Copy to first record only - Only the first record created by the split inherits the metadata of the original record. Other records created as a result of the split do not inherit ED Loader metadata, with the exception of DocID. Other user-defined field data is retained for all records.
|
||
Autonumber |
For any record created as a result of the split operation, this option will automatically number the DocID values with a suffix. To use this feature, enable the "Auto number remaining DocID's" setting in the Split Document dialog and enter the value in the "Starting Suffix" field. The default is ".002". The value in the "Starting Suffix" field value will be appended to every record created as a result of the split with the exception of the first, or original, record. The suffix will increment by one for each record. |
|
For non-ED records, the index information from the original document is applied to all new documents. This may cause duplicate values if unique fields are defined, so any duplicate values will automatically be cleared. See below for information on metadata handling for ED records. |
|---|
|
|