Return to Section Header
The Near-Duplicate & Email Thread Analysis utility scans the extracted or OCR text of individual records for similarities and flags them within the Case Database as either Near-Duplicates or Email Threads.
Near-Duplicates are records which are not entirely identical, yet may still contain similar/duplicate content within them. Identifying them is useful when trying to locate documents related to each other in ways meaningful to a particular case. Once identified by LAW, these records are organized into groups known as Clusters and Families:
•Near-Duplicate Cluster - A grouping of one or more records that are loosely related to each other in some way. All records assigned to a Cluster have a percentage of similarity at or above the Cluster Threshold specified. Records belonging to the same cluster may have no direct relationship or apparent similarity to each other, as long as some chain of relationship still exists for the entire Cluster at or above the Cluster Threshold.
•Near-Duplicate Family - A grouping of one or more near-duplicate records with a Master Document assigned to them. All records assigned to a Family have a percentage of similarity to the Master Document at or above the Family Threshold specified. The Master Document contains the greatest overall percentage of similarity to all the other records in that Family.
Email Threads are chains/groups of email messages belonging to the same conversation, including the original message, all subsequent replies, and any message attachments. They are identified by the duplicate content contained within them, such as the subject line or any previous quoted messages. Identifying them is useful in reducing the overall amount of redundant text data being processed when looking at email stores and documents, but without overlooking messages that may still contain unique information.
Tips and Considerations for Near-Duplicate Analysis
•Near-Duplicate analysis is especially helpful for finding additional records with high responsiveness, once one or more records have already been found.
•Perform OCR on any records that are not already search-able before running near-duplicate analysis. To find records without OCR text, search for any documents not containing a "C" in the OCRStatus field.
•Attachment and/or Parent documents are analyzed separately from individual records.
•Documents containing little or no text may be flagged as near-duplicates due to not having enough content to differentiate them.
•Be sure to include attachments in any searches you create if you wish to preserve the parent/child context of near-duplicates.
A Knowledge Based Article on this subject can be found here: “System.OutOfMemoryException: Exception of type 'System.OutOfMemoryException' was thrown” error with running Near Dupe on a very large case. (cloudnine.com)
 (Re)Running the Near-Duplicate & Email Thread Analysis Utility
(Re)Running the Near-Duplicate & Email Thread Analysis Utility
1.Open the Near-Duplicate & Email Thread Analysis utility from the Menu of the Main User Interface by selecting Tools > Near-Duplicate & Email Thread Analysis....
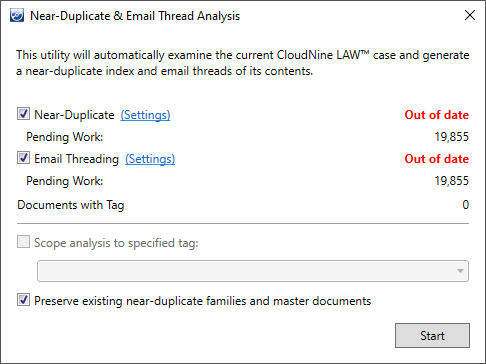
2.The utility will quickly scan the active Case Database and report back on the current Near-Duplicate and Email Thread status, including the number of records awaiting analysis.
i.If records are awaiting analysis, then the utility will indicate an Out of Date status, and will automatically enable each type of analysis that LAW recommends performing.
3.Click on (Settings) to the right of each enabled analysis to open their respective overlays, and the adjust their settings as desired (explained below).
4.You can limit the analysis to only text-tagged records by enabling the Scope analysis to specified tag option and selecting a Custom Metadata Field from the drop-down.
i.The Documents with Tag line of the utility will update to reflect the number of records tagged as Y within the selected Custom Metadata Field.
5.You can Preserve existing near-duplicate families and master documents during analysis by enabling the appropriate option at the bottom (explained below).
6.With the utility configured as desired, you can begin the analysis by clicking on Start at the bottom-right. The utility will update its progress in real-time.
7.Once completed, the utility will display an Analytics Processing Complete window with the results of the analysis.
8.When you're finished reviewing the results, click on Close at the bottom-right to exit the utility.
|
|
If you import a LAW case using the File menu > Import menu > Law Case feature, and the case's documents have already been analyzed by the Near Duplicate & Email Thread Analysis utility, the status will be displayed as Out of Date until you re-run the utility against the imported case. |
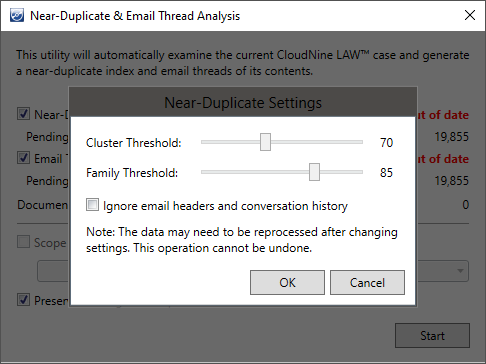
Near-Duplicate Settings•Cluster Threshold - Specifies the minimum percentage of similarity that record content must meet in order to be grouped into a Cluster. Should be lower than the Family Threshold. •Family Threshold - Specifies the minimum percentage of similarity that record content must meet in order to be grouped into a Family. Should be higher than the Cluster Threshold. A Master Document will also be determined by this threshold, which will have the highest percentage of similarity to all the other records within that Family. •Ignore email headers and conversation history - Limits email analysis to the main body of text within each message, ignoring all subject lines and previous quoted messages.
|
|
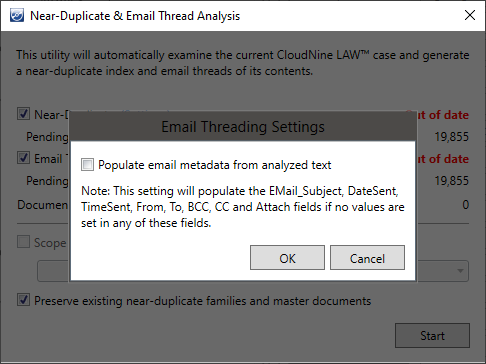
Email Threading Settings
|
Viewing Duplicates, Near-Duplicates, and Email Threads
While highlighting documents within the Case Directory pane of the Main User Interface, you can view their Duplicate/Near-Duplicate status (and associated Duplicate/Near-Duplicate documents) by referencing the Duplicate Viewer.
Additionally, you can locate and view Duplicates, Near-Duplicates, or Email Threads by searching for specific Metadata Fields within case records using the Database Query Builder. Refer below for a listing of Metadata Fields and values to search for.
In order to use the Near-Duplicate & Email Thread Analysis utility, you will need the Near-Duplicate/Email Thread license. You will also need the license to see the near-duplicate results, status, and compare near-duplicate documents from the Duplicate Viewer. The Near-Duplicate & Email Thread license is only used by LAW on an as-needed basis, so the license is only displayed in the in the LAW Profile Manager (Administration Mode). The license is not displayed in the license list in the LAW Management Console (LMC) or License Information dialog box (Help > About LAW > Licenses).