Import Tag List Import Tag List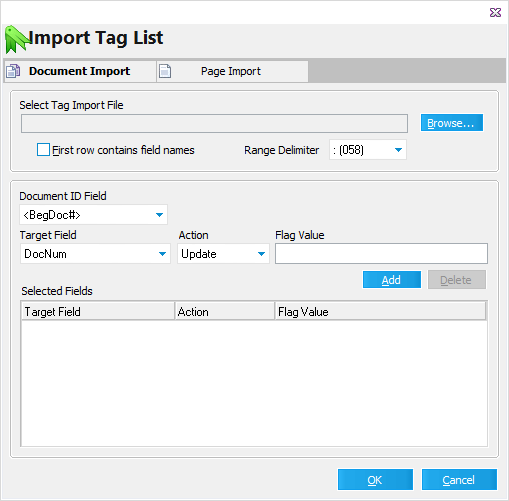
1.On the File menu, click Import and then click Tag List. The Import Tag List dialog box appears. 2.Click Browse to locate the tag import file. (*.csv , *.txt) If the import file's first record contains the field name, check the First row contains field names box. The range delimiter is used when importing ranges of records to be updated rather than a list of individual ID numbers (i.e. ID0001-ID0048).
3.Configure Target Field, Action, and Flag Value as needed. Note the following when configuring these options: •The Document ID Field lists fields that may be used to link the incoming import file with existing records. For example, if the user is provided a text file containing a list of DocIDs that match the DocIDs in the case, then the user would select DocID as the Document ID Field. •For greater performance in cases with a large number of records, it is recommended to apply an index to the selected Document ID field. You can manually apply a tag to a field by using the Modify Fields dialog box. However, CloudNine™ LAW will check for the existence of an index on the selected Document ID field. If the field is not indexed after initializing the import, LAW will allow the addition of an index for the selected Document ID field at that time. When adding an index using this method, the grid displays will need to be closed prior to adding the index. If the grid is active, LAW will display a prompt requesting the grid be closed in order to continue.
•A memo field cannot be used as the Document ID field.
•The Target Field is the field to be updated with the "tag" value. If a tag field is selected, the Flag Values will appear as "True" and "False". The Action drop-down will have two options: Update (which will update the records with the specified Flag Value) and Reverse (which ignores the Flag Value and simply toggles the current value of the tag field for each affected document). If other field types are selected, such as a text field, the Action options will change to Update (explained above) and Append, which allows users to append the specified Flag Value to any existing field data. Date fields will only have an Update option. 4.Click Add. The entry is added to Selected Fields. 5.Select additional target fields as needed. 6.Click OK. The import process starts. After the import is complete, a report appears that lists the number of records that have been updated and any errors that may have occurred during the import. These records may then be returned by a search using the filter functions or query tools.
|