|
Setting |
Description |
|---|---|---|
|
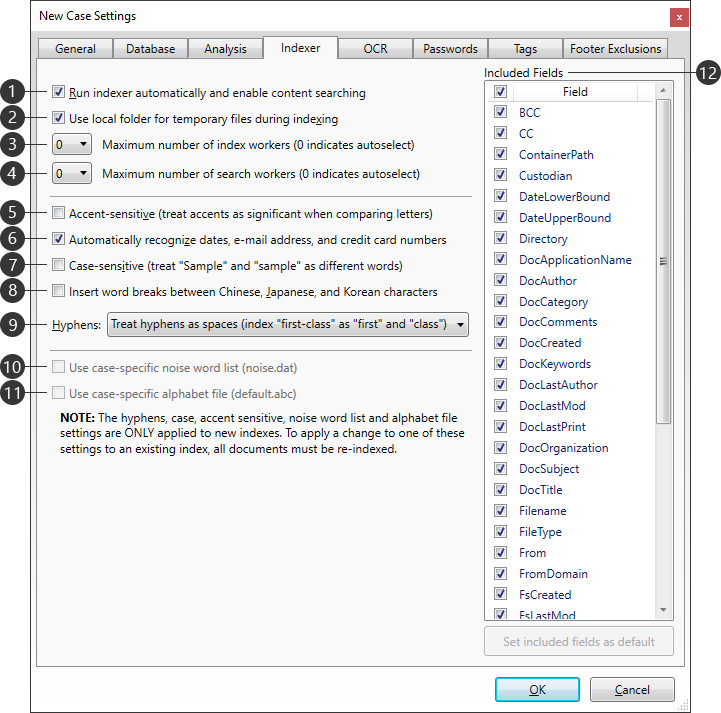
Run indexer automatically and enable content searching |
Enables case indexing and content searching for the case. The indexer will run automatically when changes are made to the case.
|
|
Use local folder for temporary files during indexing |
Instructs the indexer to use the local user’s temporary folder for files that are too large to fit into memory. These temporary files are automatically deleted once finished. This is the recommended setting for cases on network drives, NAS, or SAN devices. |
|
Maximum number of index workers |
Determines the number of workers (agents) used for indexing, up to a maximum of 16. When 0 is selected, any machine performing indexing will use 1 worker per available processor core, with a limit of 8 workers. If a machine has more than 8 cores, then only a maximum of 8 workers will be used. |
|
Maximum number of search workers |
Determines the number of workers (agents) used for searching, up to a maximum of 16. When 0 is selected, any machine running searches will use 1 worker per available processor core, with a limit of 8 workers. If a machine has more than 8 cores, then only a maximum of 8 workers will be used. |
|
Accent-sensitive |
Accents are taken into account when indexing words. Not recommended for most users, since this option increases the chance of missing document retrieval if an accent was omitted. |
|
Automatically recognize dates, e-mail addresses, and credit card numbers |
The indexer will scan for anything that looks like a date, e-mail address, or credit card number. |
|
Case-sensitive |
Capitalization is taken into account when indexing words. In a case-sensitive index, "CREDIT", "Credit", and "credit" would be three different words. This option can be useful when searching for a term, such as a capitalized name, which can be confused with a common, non-capitalized word. |
|
Insert word breaks between Chinese, Japanese, and Korean characters |
Word breaks will be automatically inserted between these characters, preventing the indexer from reading each line of text as a single long word. Recommended for documents in Chinese, Japanese, or Korean that do not contain word breaks, to aid in making this type of text search-able. |
|
Hyphens |
Determines how hyphens are indexed within text, from the following options: •All three - Hyphens are handled in multiple ways, so "first-class" is indexed as "first-class", "firstclass", "first", and "class". •Treat hyphens as search-able - Hyphens are treated like any other character, so "first-class" is indexed as "first-class". •Ignore hyphens - Hyphens are ignored, so "first-class" is indexed as "firstclass". •Treat hyphens as spaces - Hyphens are treated like spaces, so "first-class" is indexed as "first" and "class". |
|
Use case-specific noise word list |
Only available after case creation. The case-level noise.dat file will be used for identifying and excluding noise words, rather than the application-level noise.dat file. You can edit the case-level noise.dat file by clicking the Open link that appears once enabled. For more information about the application-level and case-level noise.dat files, refer to the Noise Words topic. |
|
Use case-specific alphabet file |
Only available after case creation. The case-level default.abc file will be used for identifying search-able characters, rather than the application-level default.abc file. You can edit the case-level default.abc file by clicking the Open link that appears once enabled. For more information about the application-level and case-level default.abc files, refer to the Alphabet File topic. |
|
Included Fields |
This list determines which case fields are indexed and search-able. Use the check-boxes to include/exclude individual fields, or the Field header check-box to include/exclude all fields. Cases need to be re-indexed anytime changes are made to this list. The InventoryId field is always selected and cannot be excluded. This field is required for internal processing. Use the Set included fields as default button at the bottom to make the current field choices the new default for all new cases. |
|
For more information about indexes, refer to the Managing Indexes topic. |