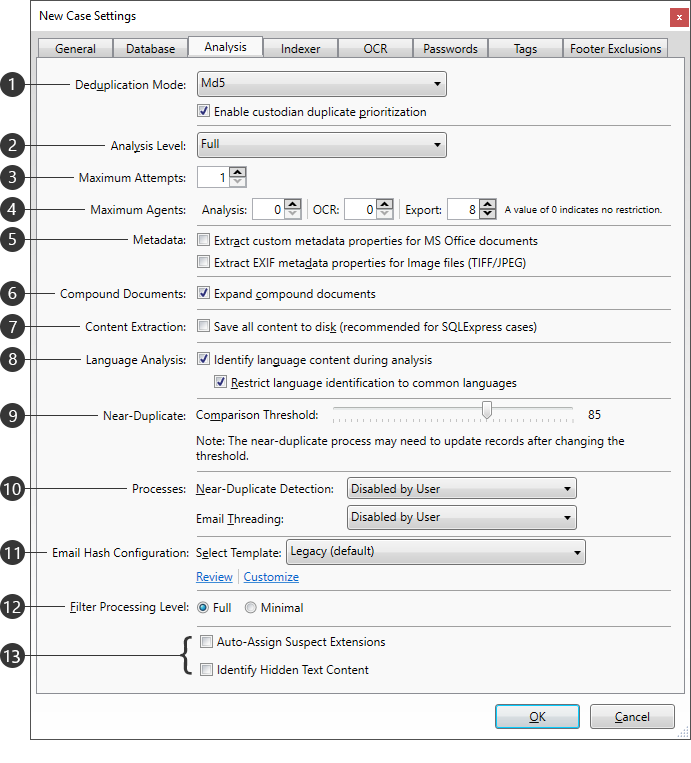
|
Setting |
Description |
|
Deduplication Mode |
Determines the hashing used to identify duplicates, from the following options: •MD5 - Uses a 128-bit string across all sources. •SHA1 - Uses a 160-bit string across all sources. •MD5Custodian - Uses a 128-bit string within each custodian. •SHA1Custodian - Uses a 160-bit string within each custodian. Custodians are managed on the Import sub-tab from the Case Dashboard. Enable custodian duplicate prioritization - Determines whether you can customize the custodian priority for deduplication in the case. When selected, the Edit link is displayed next to the Duplicates filter on the case Filters tab. The Edit link opens the Custodian Deduplication Priority dialog box. |
|
Analysis Level |
Determines how content extraction is handled, from the following options: •Full - Performs content extraction. Allows full-text searching. •No Content - Skips content extraction. Does not allow full-content searching, but may improve performance. |
|
Maximum Attempts |
Sets the limit for processing attempts made during Analysis, ranging from 1 to 5 (max). |
|
Maximum Agents |
Sets the maximum number of services (agents) that can be running concurrently during the following processes: •Analysis •OCR •Export These limits can be changed during processing. |
|
Metadata |
Extract custom metadata properties for MS Office documents - The following metadata will be extracted during import: •Comments in Microsoft Word, Excel, and PowerPoint files •Tracked changes in Word and Excel files •Hidden rows and/or columns in Excel files •Hidden worksheets in Excel files •"Very hidden" worksheets in Excel files •Hidden slides in PowerPoint files •Speaker notes in PowerPoint files Extract EXIF metadata properties for Image files (Tiff/JPEG) - Custom metadata properties (EXIF) from TIFF and JPEG files will be extracted during Analysis. |
|
Compound Documents |
Expand compound documents - Documents containing embedded files will be expanded and imported separately, treating embedded files as attachments to their parent document and making them search-able. Refer to the Extracting Compound Documents topic for more information. |
|
Content Extraction |
Save all content to disk - Prevents the storage of content directly within the Case Database. This setting can help to avoid reaching the maximum database size limitations imposed by SQL Express. |
|
Language Analysis |
Identify language content during analysis - Languages will be identified during the analysis phase of the file import process. Restrict language identification to common languages - Restricts language identification to to common languages, which can help improve the overall accuracy. The first 200 MB of each document is analyzed to identify the language used. |
|
Near-Duplicate |
Comparison Threshold - Determines the minimum percentage of similarity to be considered when comparing case files during near-duplicate analysis. Can be adjusted to any value between 60 and 90 percent. When significant changes are made to this setting, the near-duplicate analysis will re-run automatically. For more information about the Comparison Threshold setting and near-duplicate analysis, refer to the Near-Duplicate & Email Thread Analysis and Running Near-Duplicate & Email Thread Analysis topics. |
|
Processes |
Near-Duplicate Detection - Determines when near-duplicate analysis will be performed for the case, from the following options: •Start Automatically - Near-duplicate analysis will start automatically for new cases or when changes are made to the case data, such as changing the Comparison Threshold or importing additional files into the case. •Disabled by User - Near-duplicate analysis is disabled, and stopped if currently running. Email Threading - Determines when email thread analysis will be performed for the case, from the following options: •Start Automatically - Email thread analysis will start automatically for new cases or when changes are made to the case data, such as importing additional files into the case or deleting files from the case. •Disabled by User - Email thread analysis feature is disabled, and stopped if currently running. For more information about near-duplicate analysis, refer to the Near-Duplicate & Email Thread Analysis and Running Near-Duplicate & Email Thread Analysis topics. |
|
Email Hash Configuration |
Allows users to determine which metadata fields are used when generating hash values for email comparison, both in terms of which fields are included and which order they are applied. Select Template - Select between various preconfigured hashing templates for use in the current case. Review - Shows all available templates, along with the fields being used. Customize - Allows you to modify the selected template. Users cannot select a different template once importing has occurred, but the chosen template may be modified at any time, which will trigger a re-hashing of all emails in the case. |
|
Filter Processing Level |
Sets the amount of filters to be used in the case, from the following options: •Full - Includes the following filters: File Hash Filter (NIST Items and Custom File Hash Items), Duplicate Document filter, Date Range Filter, File Type Filter, E-Mail Sender Domain Filter, and Language Filter •Minimal - Includes only the following essential filters, which will be run post-analysis: File Hash Filter (NIST Items and Custom File Hash Items), Duplicate Document filter This setting cannot be changed once analysis has begun. |
|
|
Auto-Assign Suspect Extensions - If this option is selected, the FileExtension field is populated with the source file type detected during import if the source file extension does not match that type. This option cannot be selected unless you have a File Type Management database configured. Identify Hidden Text Content - If this option is selected, during analysis, Explore identifies hidden text and provides it in the extracted text within <<<Start Hidden Content>>> and <<<End Hidden Content>>> markers. The HasHiddenText field will also be set. |